Realtime visualization of 3D vector fields using CUDA
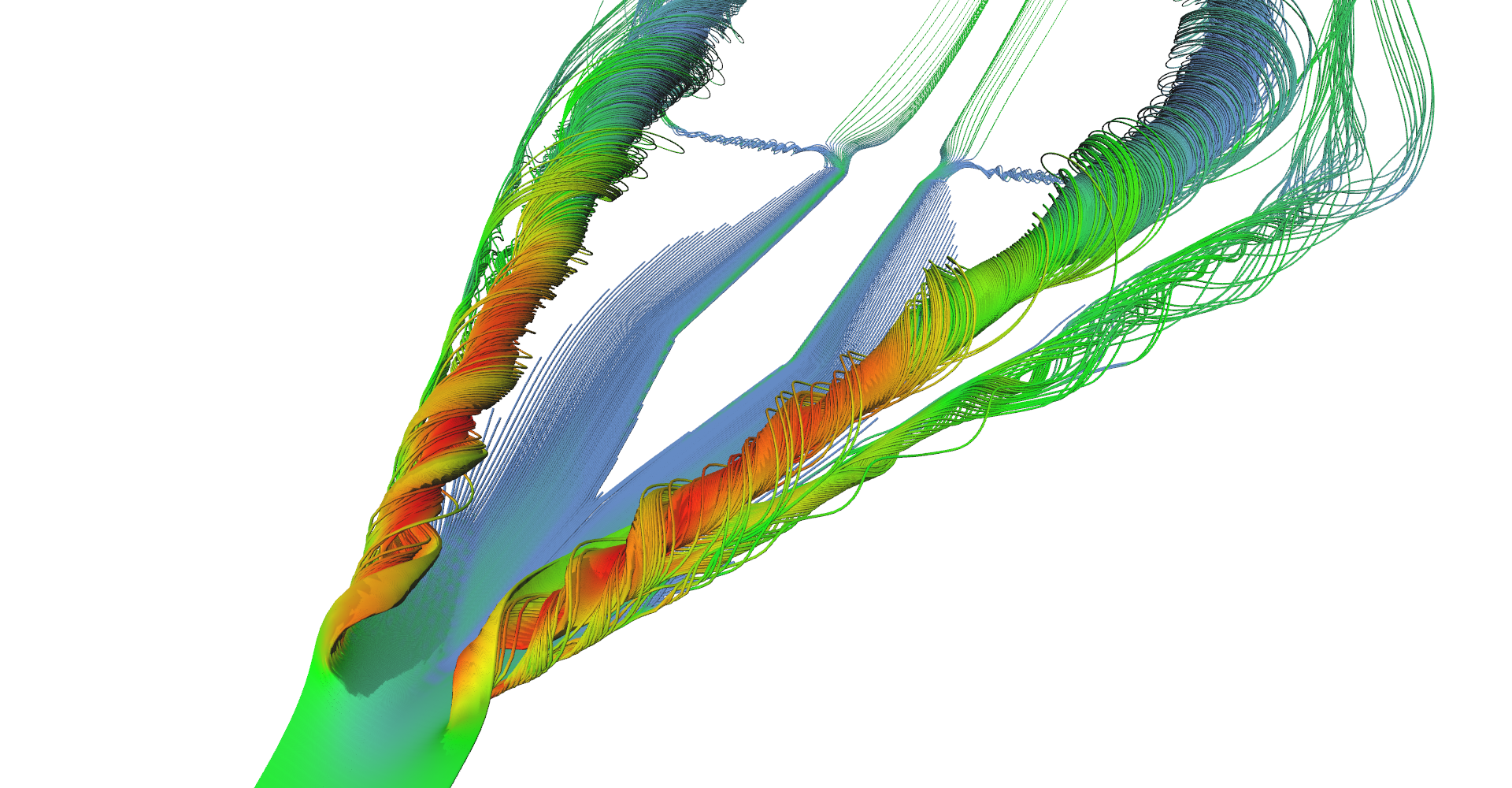
This project demonstrates visualization techniques like glyphs, stream lines, stream tubes, and stream surfaces — all done in real time. The key is RK4 integrator implemented using CUDA that is uses very fast texture lookup functions to access a vector field. This article contains more than 100 images and figures, commented code snippets, and source code available for download.
Source code is available on GitHub: NightElfik/Vector-field-visualization-using-cuda
Stream tubes seeded near the tip of the delta-wing. 
Detail on the stream surface of the primary vortex. 
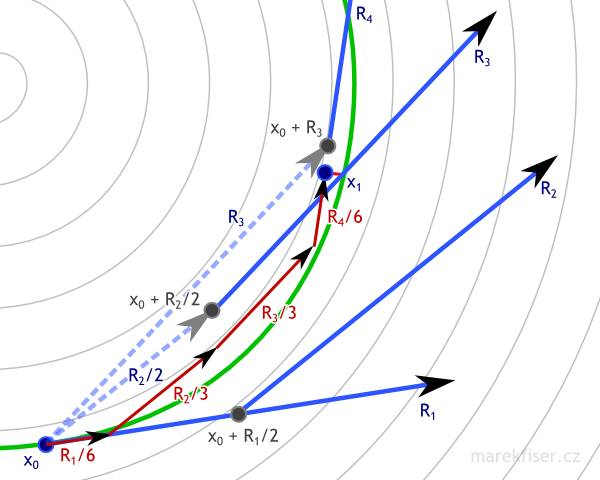
Explanation of Runge–Kutta 4 integration. 
Stream surface combined with stream lines. 
Benchmark of the system. 
Adaptive triangulation.



Chapter 1: Introduction
Vector field visualization is special case of flow visualization where the flow is "frozen" (in time). Such a "frozen" fluid flow can be represented as vector field which gives us information about the speed and direction of the fluid in any given point. For practical reasons we usually have only finite number samples within observed volume and vector in arbitrary location is computed using some kind of interpolation. Flow visualizations are important all kinds of engineering like airplane or car design.
The topic of this project is visualization of vector field using various techniques like stream lines, stream tubes, stream surfaces and glyphs. This project was final assignment in Introduction to Scientific Visualization class (CS 530). The assignment was meant to be implemented using open-source library called Visualization Toolkit (VTK) but I decided to implement it completely from scratch hoping that I will learn a lot of new things which turned out to be very true. Also, my implementation uses CUDA for acceleration of computation on GPU to achieve interactivity. Full source code is available on GitHub.
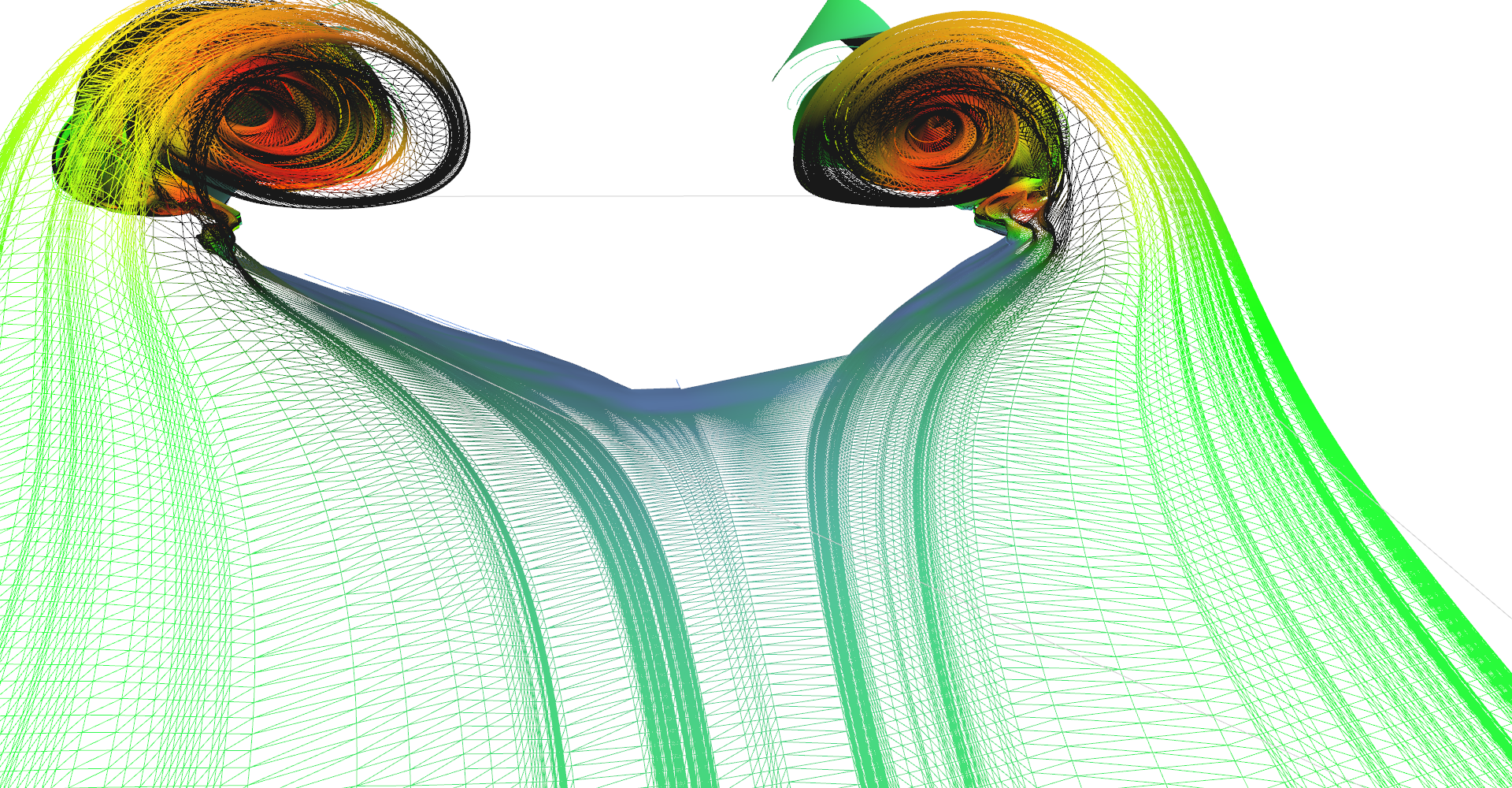
 Figure 1: Stream line visualization of air flow around delta wing.
Figure 1: Stream line visualization of air flow around delta wing.Dataset
The input for this visualization is pre-computed 3D vector field of air flowing around delta-wing (see Fig. Figure 2). I believe that dataset which was given to us is available somewhere on the Internet however I had no luck in finding it.
I was working with two versions of the dataset:
- Small 400×200×150 (138 MB raw)
- Large 800×400×300 (1.1 GB raw)
The only catch of the dataset is that spacing of samples is 1×1×0.5 which makes absolute size of the last dimension two times smaller.
All images on this page were made using large dataset.

Delta-wing model from the top. 
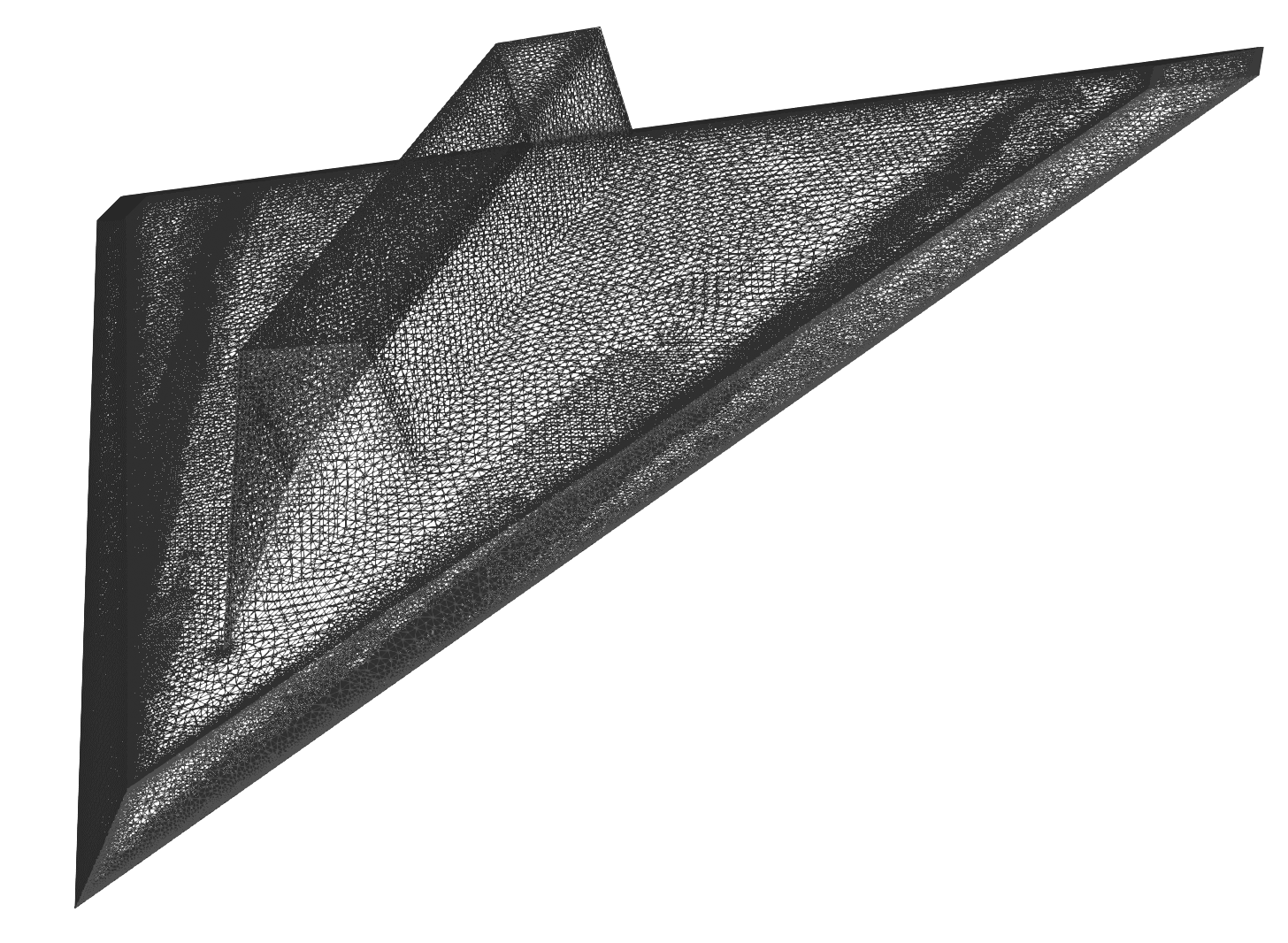
Delta-wing wireframe model - mesh is pretty detailed. 
Delta-wing model from the bottom - you can see the aerodynamic box on the bottom. 
Another picture of delta-wing model from the bottom.



Loading input
Input dataset is in NRRD file format which is basically plain text header information followed by
raw uncompressed data.
In my case data is 3D array of 3D floating-point vectors which makes it 4D array of floats.
This 4D array is linearized with first dimension varying the fastest.
Header from the large dataset is shown in Code listing 1.
Complete NRRD file format specification can be found at http://teem.sourceforge.net/nrrd/format.html.
1
2
3
4
5
6
7
8
9
NRRD0001
type: float
dimension: 4
sizes: 3 800 400 300
spacings: 1 1.0012515783 1.0025062561 0.50167226791
axis mins: 0 -150 -200 -50
labels: "Vx;Vy;Vz" "x" "y" "z"
endian: little
encoding: raw
Because I decided to not use VTK, I had to write my own reader but it was pretty straight forward. The only thing I would like to mention here is how easily can be binary data read from binary stream. Code listing 2 shows a main cycle of reading vector field.
Notice that I am using 4D vector (instead of 3D) for storing the vector field. Fourth dimension is used for storing vector magnitude, details are explained in next section.
The only catch here is endianness. I am silently assuming that endianness of the file matches endianness of my CPU which is true, both are little-endian.
1
2
3
4
5
6
7
8
9
10
11
12
13
std::ifstream inputStream(filePath, std::ios::binary);
// Reading of header information skipped.
// ... float3 size initialized with size of VF
size_t totalSize = size.x * size.y * size.z;
float4* data = new float4[totalSize];
for (size_t i = 0; i < totalSize; ++i) {
float4* f4Ptr = &(data[i]);
// Read x, y, z.
inputStream.read((char*)f4Ptr, sizeof(float3));
// Compute magnitude as w.
curr->w = std::sqrtf(f4Ptr->x * f4Ptr->x + f4Ptr->y * f4Ptr->y + f4Ptr->z * f4Ptr->z);
}
Fast reading of volumetric data using CUDA
The core of any visualization technique is reading values at any point within given 3D vector field. Since input is discrete gird, linear interpolation is needed for reading point which is not on the grid (basically 100% of the queries).
This is the first place where CUDA will kick in.
CUDA offers very fast functions for reading 3D textures with linear interpolation which is exactly what is needed here.
However only supported types are float1, float2 or float4
(no float3) but this led to another advantage.
I've used fourth dimension of float4 for storing vector magnitudes which are computed while parsing data from file.
This will significantly speed up visualization.
The only disadvantage is that this will increase memory consumption by 1/3 which is quite big deal when we are speaking about GPU memory.
Loading initialization of 3D texture and loading data to GPU is shown in Code listing 3. Reading of vector data at arbitrary position is as simple as:
1
float4 vector = tex3D(vectorFieldTex, x, y, z);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
texture<float4, cudaTextureType3D, cudaReadModeElementType> vectorFieldTex;
cudaArray* d_volumeArray = nullptr;
void initCuda(const float4* h_volume, cudaExtent volumeSize) {
// Allocate 3D array.
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float4>();
cudaMalloc3DArray(&d_volumeArray, &channelDesc, volumeSize);
// Copy data to 3D array using pitched ptr.
cudaMemcpy3DParms copyParams = {0};
copyParams.srcPtr = make_cudaPitchedPtr((void*)h_volume,
volumeSize.width * sizeof(float4), volumeSize.width, volumeSize.height);
copyParams.dstArray = d_volumeArray;
copyParams.extent = volumeSize;
copyParams.kind = cudaMemcpyHostToDevice;
// Set texture parameters.
vectorFieldTex.normalized = false;
vectorFieldTex.filterMode = cudaFilterModeLinear;
vectorFieldTex.addressMode[0] = cudaAddressModeClamp;
vectorFieldTex.addressMode[1] = cudaAddressModeClamp;
vectorFieldTex.addressMode[2] = cudaAddressModeClamp;
// Bind 3D array to 3D texture.
cudaBindTextureToArray(vectorFieldTex, d_volumeArray, channelDesc);
}
Color gradient for magnitude visualization
Magnitude of vectors is very important for visualization because it represents velocity of the air flow.
I chose linear blue-green-red gradient to represent the magnitude where blue represents the lowest magnitude in the dataset
and red the highest (Figure 3).
This gradient is stored and queried in the same fashion as main vector data.
Colors values are saved in 1D texture on GPU and CUDA command tex1D is used for fetching interpolated value.
 Figure 3: Color gradient used for visualization of vector magnitudes
Figure 3: Color gradient used for visualization of vector magnitudesOpenGL CUDA interoperability
Great advantage of using CUDA in this type of application is that very little data needs to be transferred between CPU and GPU. The only data which needs to be transferred from CPU to GPU are start positions (seeds) and it usually very few data (units of kilobytes). Results of CUDA computations are left in GPU memory and immediately displayed using VBOs.
Code listing 4 shows how shared VBOs are initialized. First, OpenGl VBO is created and then CUDA buffer obtained from VBO. This ensures than both VBO pointer and CUDA device pointer will point to the same chunk of GPU memory.
Code listing 5 shows simplified usage of interoperability between OpenGL VBOs and CUDA.
Function allocate just allocates needed memory for CUDA kernel invocation (shown in Code listing 4).
Function recompute invokes CUDA kernel which will write results to provided memory which is VBO mapped buffer.
Function cudaGraphicsMapResources tells GPU that this memory will be accessed by CUDA
and if you try it to use with OpenGL before unmapping, bad things will happen to you (e.g. your program).
Function cudaGraphicsResourceGetMappedPointer will retrieve device pointer from mapped VBO.
The last function in Code listing 5 called displayCallback will bind VBOs and render them.
Super fast, super efficient, I love it!
1
2
3
4
5
6
7
8
9
cudaError_t createCudaSharedVbo(GLuint* vbo, GLenum target, uint size,
cudaGraphicsResource** cudaResource) {
glGenBuffers(1, vbo);
glBindBuffer(target, *vbo);
glBufferData(target, size, 0, GL_DYNAMIC_DRAW);
glBindBuffer(target, 0);
return cudaGraphicsGLRegisterBuffer(cudaResource, *vbo, cudaGraphicsMapFlagsNone);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
void allocate() {
createCudaSharedVbo(&m_verticesVbo, GL_ARRAY_BUFFER,
verticesCount * sizeof(float3), &m_cudaVerticesVboResource);
createCudaSharedVbo(&m_colorsVbo, GL_ARRAY_BUFFER,
verticesCount * sizeof(float3), &m_cudaColorsVboResource);
}
void recompute() {
size_t bytesCount;
float3* d_glyphs;
cudaGraphicsMapResources(1, &m_cudaVerticesVboResource);
cudaGraphicsResourceGetMappedPointer((void**)&d_glyphs, &bytesCount,
m_cudaVerticesVboResource);
float3* d_colors;
cudaGraphicsMapResources(1, &m_cudaColorsVboResource);
cudaGraphicsResourceGetMappedPointer((void**)&d_colors, &bytesCount,
m_cudaColorsVboResource);
runCudaKernel(..., d_glyphs, d_colors, m_glyphsCount, ...);
cudaGraphicsUnmapResources(1, &m_cudaColorsVboResource);
cudaGraphicsUnmapResources(1, &m_cudaVerticesVboResource);
}
void displayCallback() {
glBindBuffer(GL_ARRAY_BUFFER, m_verticesVbo);
glEnableClientState(GL_VERTEX_ARRAY);
glVertexPointer(3, GL_FLOAT, 0, NULL);
glBindBuffer(GL_ARRAY_BUFFER, m_colorsVbo);
glEnableClientState(GL_COLOR_ARRAY);
glColorPointer(3, GL_FLOAT, 0, NULL);
glDrawArrays(GL_LINES, 0, 2 * m_glyphsCount.x * m_glyphsCount.y);
}