Conway's Game of Life on GPU using CUDA
Chapter 3: Advanced implementation: 1 bit per cell
I was quite satisfied with 140x speedup of the basic GPU implementation over the serial CPU but I decided to boost GPU's ego even further by hopefully faster implementation. Actually – two implementations. This chapter explains an easier one, next Chapter 4: Advanced implementation: lookup table talks about more complicated one.
Every life cell has two states (alive or dead) which were so far represented as integers 1 and 0. I asked myself a question:
Usage of 1 bit per cell could be potentially more efficient and it could also cut memory requirements 8-times.
So how to speed up cell state evaluation?
The obvious way is to get rid of the summing part that is slow because it has too many memory reads — 8 memory reads per cell to be exact.
If a life cell would be stored in one bit, a single read of a byte would actually read 8 cells.
Even further, a single read of unsigned int (uint) retrieves 32 cells at once.
The idea of bit per cell sounds promising, but there is a little catch.
Cells in one uint are in a row, but area of 3x3 cells is needed in order to evaluate a single cell.
This means that three rows are needed, but it is still better than 9 memory reads.
Evaluation of the cells
The goal is to evaluate whole byte of data (8 cells). It is necessary to load three rows and then it is possible to evaluate the middle row cell by cell by counting the number of living cells. The problem is that the neighborhood area overlaps to bytes before and after the current block as shown in Figure 7. This adds quite large overhead. Instead of reading 3 bytes and evaluating 1 byte, 9 bytes need to be read.
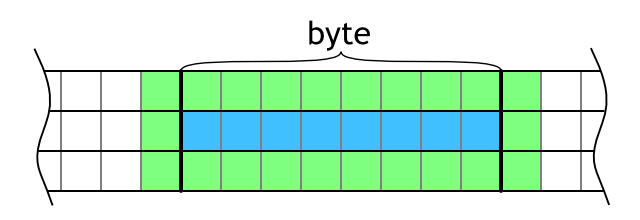 Figure 7: Evaluation of a byte of data (blue area) needs cells from neighboring bytes (green area).
Figure 7: Evaluation of a byte of data (blue area) needs cells from neighboring bytes (green area).This overhead can be significantly reduced by evaluating more consecutive block in the row as shown in Figure 8. Actually, the overhead is constant — 2×3 bytes — no matter how many blocks are evaluated in between them. This means that the more bytes evaluated in the row, the better. However, more blocks in the row means more work per thread and too much work per thread can stall the GPU which is not good.
It is hard to guess what is the magical number of consecutive processed blocks (bytes) that would result in the best performance; I will leave this as a parameter of the method.
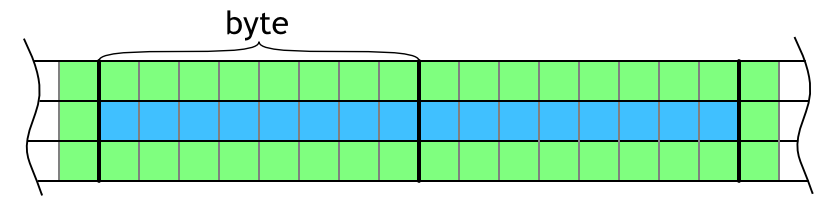 Figure 8: Visualization of overlapping neighboring cells on the left and right. Blue area shows evaluated cells and green area highlights neighbors that are necessary for evaluation.
Figure 8: Visualization of overlapping neighboring cells on the left and right. Blue area shows evaluated cells and green area highlights neighbors that are necessary for evaluation.GPU implementation
Code listing 9 shows the CUDA kernel. It is quite lengthy but I will try to describe it in detail in following paragraphs.
The kernel starts with a scary-looking for-cycle. This cycle ensures that if the kernel is invoked with less threads then cells to process, every thread will loop through more cells to compute all of them.
The first thing computed in the main cycle is x and y coordinates based on given cell ID. All y coordinates are pre-multiplied with data width to avoid unnecessary multiplications later. This is necessary since the data are stored in 1D array and every y index has to skip whole row (data width).
Then, variables called data0, data1, and data2 are initialized with first two bytes of data.
Those 4-byte (32-bit) integer variables represent rows of data and they are used to store three consecutive bytes of data to allow easy evaluation of the middle byte.
Next follows the for-cycle that goes over consecutively evaluated bytes.
This concept was explained in previous section Evaluation of the cells.
At the beginning of the cycle, a new byte is pushed to the datan variables by left-shifting existing content by 8 and or-ing new byte.
Then, another cycle goes over 8 cells that are evaluated. At every position, number of living cells is counted by some (clever) bit operations and based on the sum the result bit is written. Feel free to grab a piece of paper and sketch the bit operations to see what is happening. Basically, it is parallel bit summing on two positions and then summing to the final number.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
__global__ void bitLifeKernelNoLookup(const ubyte* lifeData, uint worldDataWidth,
uint worldHeight, uint bytesPerThread, ubyte* resultLifeData) {
uint worldSize = (worldDataWidth * worldHeight);
for (uint cellId = (__mul24(blockIdx.x, blockDim.x) + threadIdx.x) * bytesPerThread;
cellId < worldSize;
cellId += blockDim.x * gridDim.x * bytesPerThread) {
uint x = (cellId + worldDataWidth - 1) % worldDataWidth; // Start at block x - 1.
uint yAbs = (cellId / worldDataWidth) * worldDataWidth;
uint yAbsUp = (yAbs + worldSize - worldDataWidth) % worldSize;
uint yAbsDown = (yAbs + worldDataWidth) % worldSize;
// Initialize data with previous byte and current byte.
uint data0 = (uint)lifeData[x + yAbsUp] << 16;
uint data1 = (uint)lifeData[x + yAbs] << 16;
uint data2 = (uint)lifeData[x + yAbsDown] << 16;
x = (x + 1) % worldDataWidth;
data0 |= (uint)lifeData[x + yAbsUp] << 8;
data1 |= (uint)lifeData[x + yAbs] << 8;
data2 |= (uint)lifeData[x + yAbsDown] << 8;
for (uint i = 0; i < bytesPerThread; ++i) {
uint oldX = x; // old x is referring to current center cell
x = (x + 1) % worldDataWidth;
data0 |= (uint)lifeData[x + yAbsUp];
data1 |= (uint)lifeData[x + yAbs];
data2 |= (uint)lifeData[x + yAbsDown];
uint result = 0;
for (uint j = 0; j < 8; ++j) {
uint aliveCells = (data0 & 0x14000) + (data1 & 0x14000) + (data2 & 0x14000);
aliveCells >>= 14;
aliveCells = (aliveCells & 0x3) + (aliveCells >> 2)
+ ((data0 >> 15) & 0x1u) + ((data2 >> 15) & 0x1u);
result = result << 1
| (aliveCells == 3 || (aliveCells == 2 && (data1 & 0x8000u)) ? 1u : 0u);
data0 <<= 1;
data1 <<= 1;
data2 <<= 1;
}
resultLifeData[oldX + yAbs] = result;
}
}
}
CPU implementation and performance evaluation
A CPU implementation of the bit counting algorithm is nearly identical to the GPU implementation. The implementation is parallel and I did not even investigate a serial version of it. If you are interested in actual implementation details please see the code on GitHub.
The performance of the CPU version was evaluated for wide range of consecutive evaluated blocks (cb). The evaluation speeds are shown in Figure 9. The basic serial and parallel algorithms are shown in the figure for comparison.
Figure 9 clearly shows that the bit-per-cell algorithm is much faster than the basic one saving not only memory but speeding the evaluation as well. As expected, the more consecutive evaluated blocks (cb) the better. This is not the case for GPU as you can see in the next section.
GPU performance evaluation
GPU performance charts are a little harder to produce because there are two parameters that could vary: number of consecutive evaluated blocks and threads per CUDA block. The benchmark was run for all combinations of those two parameters the best for each of them was reported.
The best performance among threads per CUDA block was for value 128. Figure 10 shows evaluations speeds different values of consecutive evaluated blocks (cb) compared to the basic GPU implementation described in Chapter 2: Basic implementation. For the most values of cb the evaluation speed higher than the basic GPU implementation. However, the trend that more cb results in better performance as observed in the CPU implementation is not true now. The best value of cb is probably 8, for higher values the performance decreases and for 128 cb the evaluation speed is even lower than for the basic implementation.
For the completeness of the GPU implementation performance evaluation, Figure 11 shows the evaluation speed for different values of threads per CUDA block (tpb). The variance in results in not that big, the only outlier is the lowest value 32 tpb.
This chart nicely shows the speedup of the bit counting implementation over the basic GPU implementation which is about 2.5×. That is more than speedup for the CPU implementation which was about 2×.
Next section compares performance of best performing settings of the CPU and GPU algorithms.
CPU vs. GPU
For the final comparison of this chapter, the best performing settings were selected for the CPU and GPU. The CPU algorithm performed the best for 128 consecutive evaluated blocks (cb) and the GPU algorithm for 8 cb 128 threads per CUDA block (tpb). Figure 12 shows speedup of those two measurements and compares them with the basic parallel CPU and basic GPU for 128 tbp.
It is nicely visible that even the improved bit-per-cell CPU implementation is way slower than the basic GPU implementation. The improved GPU implementation is reaching speedups up to 480× over the basic serial CPU implementation.
Optimized memory access
But I will not stop here. As suggested in introduction of this chapter, reading of larger memory blocks might be more effective. Most hardware is optimized to read larger memory block as opposed to small ones. The idea is to read and write 32-bit words instead of 8-bit bytes.
The implementation has to be substantially changed in order to achieve this improvement. First, three consecutive blocks cannot be accumulated in one variable anymore.
Second, the CPU and GPU is using little endian for representing longer words than a byte. However, little endian stores the bytes in reversed order and it is not possible to process them sequentially. This problem is solved by swapping endianness while reading and writing.
The GPU implementation is shown in Code listing 10 and it is much longer than previous implementation. This is mainly due to overlaps that are handled separately to save memory and computations.
The implementation on CPU is again very similar to the CUDA kernel and uses Concurrency::parallel_for for parallelization.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
__global__ void bitLifeCountingBigChunks(const uint* lifeData, uint worldDataWidth,
uint worldHeight, uint chunksPerThread, uint* resultLifeData) {
uint worldSize = (worldDataWidth * worldHeight);
for (uint cellId = (__mul24(blockIdx.x, blockDim.x) + threadIdx.x) * chunksPerThread;
cellId < worldSize;
cellId += blockDim.x * gridDim.x * chunksPerThread) {
uint x = (cellId + worldDataWidth - 1) % worldDataWidth; // Start at block x - 1.
uint yAbs = (cellId / worldDataWidth) * worldDataWidth;
uint yAbsUp = (yAbs + worldSize - worldDataWidth) % worldSize;
uint yAbsDown = (yAbs + worldDataWidth) % worldSize;
uint currData0 = swapEndianessUint32(lifeData[x + yAbsUp]);
uint currData1 = swapEndianessUint32(lifeData[x + yAbs]);
uint currData2 = swapEndianessUint32(lifeData[x + yAbsDown]);
x = (x + 1) % worldDataWidth;
uint nextData0 = swapEndianessUint32(lifeData[x + yAbsUp]);
uint nextData1 = swapEndianessUint32(lifeData[x + yAbs]);
uint nextData2 = swapEndianessUint32(lifeData[x + yAbsDown]);
for (uint i = 0; i < chunksPerThread; ++i) {
// Evaluate front overlapping cell.
uint aliveCells = (currData0 & 0x1u) + (currData1 & 0x1u) + (currData2 & 0x1u)
+ (nextData0 >> 31) + (nextData2 >> 31) // Do not count middle cell.
+ ((nextData0 >> 30) & 0x1u) + ((nextData1 >> 15) & 0x1u)
+ ((nextData2 >> 16) & 0x1u);
// 31-st bit.
uint result = (aliveCells == 3 || (aliveCells == 2 && (nextData1 >> 31)))
? (1u << 31) : 0u;
uint oldX = x; // Old x is referring to current center cell.
x = (x + 1) % worldDataWidth;
currData0 = nextData0;
currData1 = nextData1;
currData2 = nextData2;
nextData0 = swapEndianessUint32(lifeData[x + yAbsUp]);
nextData1 = swapEndianessUint32(lifeData[x + yAbs]);
nextData2 = swapEndianessUint32(lifeData[x + yAbsDown]);
// Evaluate back overlapping cell.
aliveCells = ((currData0 >> 1) & 0x1u) + ((currData1 >> 1) & 0x1u)
+ ((currData2 >> 1) & 0x1u)
+ (currData0 & 0x1u) + (currData2 & 0x1u) // Do not count middle cell.
+ (nextData0 >> 31) + (nextData1 >> 31) + (nextData2 >> 31);
// 0-th bit.
result |= (aliveCells == 3 || (aliveCells == 2 && (currData1 & 0x1u))) ? 1u : 0u;
// The middle cells with no overlap.
for (uint j = 0; j < 30; ++j) {
uint shiftedData = currData0 >> j;
uint aliveCells = (shiftedData & 0x1u) + ((shiftedData >> 1) & 0x1u)
+ ((shiftedData >> 2) & 0x1u);
shiftedData = currData2 >> j;
aliveCells += (shiftedData & 0x1u) + ((shiftedData >> 1) & 0x1u)
+ ((shiftedData >> 2) & 0x1u);
shiftedData = currData1 >> j;
// Do not count middle cell.
aliveCells += (shiftedData & 0x1u) + ((shiftedData >> 2) & 0x1u);
result |= (aliveCells == 3 || (aliveCells == 2 && (shiftedData & 0x2))
? (2u << j) : 0u);
}
resultLifeData[oldX + yAbs] = swapEndianessUint32(result);
}
}
}
Performance evaluation of optimized memory access
Long story short, the promise of some speedup did not happen. Figure 13 shows speedup of the bit counting algorithm on big chunks for the CPU over the previous implementation of bit counting on smaller chunks. For any value of cb the speedup is lower than one. The situation is the same for the GPU, no speedup over the previous implementation as shown in Figure 14.
First, I was quite surprised by this result but then I realized that the overhead of reading small chunks is completely negated by caches.
I think that the lower performance is caused by overhead of dealing with large chunks (endianness switching, etc.). The algorithm for smaller chunks is actually faster. Thanks, caches!